기존 PRML 책에서 나온 예제들을 통해서 Bayesian network에 대해 깊숙히 이해해보고자 한다.
신경망 학습을 위해서 가장 중요한 것은 파라미터를 어떻게 하면 줄여서 학습 로드를 감소시킬 수 있는지가 중요하다.
픽셀 256개의 이미지면 2의 256승 -1의 파라미터를 가지고 있기에, 이대로 학습을 돌릴 수 없으니,
어떻게 파라미터를 감소시키는지를 이해할 필요가 있다.
특히 Generative model에서는 X자체의 확률 분포 P(X)나, P(X,Y)를 학습하는것이 목표인데,
이 확률 분포를 통째로 학습하기에는 2^n-1이 너무 많으니 파라미터를 줄이면서 학습을 잘 해보자가 핵심이라고 볼 수 있다.
각각의 x가 서로 독립적이라면 아래와 같은 수식으로 나타낼 수 있다.

여기서 존재할 수 있는 가능한 상태(조합)는 2^n이다. 따라서 파라미터는 n개로 볼 수 있다.
만약에 x가 서로 독립적이지 않다면 파라미터는 2^n-1이다.
그런데 실제로 모든 x들끼리 전부 독립일 경우는 없으니, n개로 파라미터가 줄어들 일은 없을 것이다.
그래서 여기서 마르코프 가정을 해보자. 어떤 X_i는 직전 X_i-1에게 영향을 받게 된다면

이러한 joint probability로 수식을 짤 수가 있다.
여기서도 마찬가지로 가능한 상태는 2의 n승이다.
파라미터는 2n-1개로 볼 수 있다.

2번째 X 입장에서, 첫번째 X가 0일때 자기가 될 수 있는게 하나이므로, 파라미터는 하나이고, 그 반대의 경우에도 1개이므로
총 2개의 파라미터가 필요하다. 그렇게 1 + (n - 1) X 2 = 2n - 1개이다.
물론 여기서도 직전 state에만 영향을 받고 있기 때문에 또 다른 현실적인 가정이 필요하다.
이러한 마르코프 모델의 한계를 극복하기 위해서 Bayesian network를 적용한다.
앞서 베이지안 네트워크는 8.1 블로그로 포스팅했으니 예시로 넘어가보자.

나이브 베이지안 모델로 스팸 메일을 체크해보자.
spam은 Y = 1, 0으로 1일때에는 스팸, 0일 경우에는 스팸메일이 아닌걸로 파악한다.
각 x, 즉 메일의 단어들은 서로 모두 독립의 관계를 갖는다.
(실제로 독립이 아니겠지만 간단하게 독립이라고 가정을 하기에 naive라고 한다)
그러면 위 그림을 아래와 같이 나타낼 수 있다.
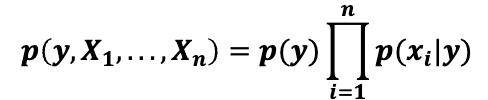
이제 미리 훈련할 데이터를 준비해서 (라벨된 데이터), 이메일 여러개와 스팸 메일 여부를 학습시킨다.
스팸과 스팸이 아닐 일반적인 비율 P(Y)를 학습하게 되면 P(Y = 1)과 P(Y = 0)인 확률을 구할 수 있다.
그리고 특정 단어들 P(Xi|Y)를 학습할 수 있다. P(Xi|Y)를 통해서 특정 단어들이 스팸 메일이 될 수 있음을 나타낸다.
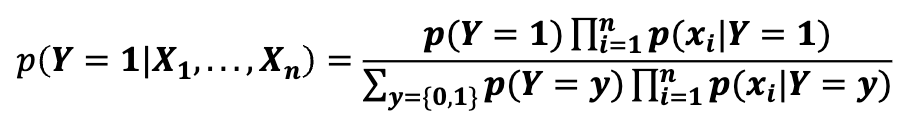
따라서 위 식으로 스팸메일인지 아닌지를 간단하게 구할 수 있다.

지금 본 Naive Bayes model은 generative model이다.
생성형 모델은 Y를 통해 X를 생성하고 판별 모델은 그 반대의 경우다.
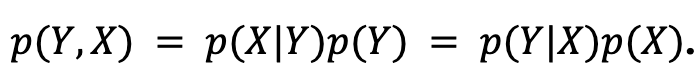
생성형 모델의 경우에는 데이터의 전체 분포를 가지고 있어서 X를 생성하기에는 좋으나, P(Y|X)를 직접 학습하는 것이 아니어서 판별 모델보다 정확도는 떨어질 수 있으나 판별 모델의 경우에는 X를 기준으로 Y를 판별하기에 데이터를 생성할 수 있는 구조는 아니다.
'PRML > Chapter 8. Graphical Models' 카테고리의 다른 글
| 8.4 그래프 모델에서의 추론 (Inference in Graphical Models)_(1) (0) | 2022.09.28 |
|---|---|
| 8.3 마르코프 무작위장 (Markov network) (0) | 2022.09.16 |
| 8.2 조건부 독립(Conditional Independence) (0) | 2022.09.16 |
| 8.1 베이지안 네트워크 (Bayesian Network) (1) | 2022.09.11 |